Низкоуровневый анализ блочных устройств Linux

Photo by Vincent Botta on Unsplash
Добрый день, коллеги!
В данной статье я хотел бы рассказать и показать как проводить низкоуровневый анализ производительности и работы блочных устройств в Linux.
Для работы на потребуется утилита blktrace, установка в CentOS 7 выглядит следующим образом:
[root@centos7 ~]# yum install -y blktrace
Первое что нам нужно сделать это, запустить запись дампа, всех событий отправленных на устройство.
[root@centos7 blktrace]# blktrace -d /dev/sda -o sda
В данной команде мы указываем через ключ -d наше устройство, и через ключ -o файл который будет содержать наш дамп.
Файл дампа бинарный, и что бы вывести содержимое в человекочитаемом виде запустим утилиту blkparse(которая входит в пакет blktrace).
[root@centos7 blktrace]# blkparse -i sda.blktrace.0 Input file sda.blktrace.0 added 8,2 0 1 0.000000000 1322 A FWS 0 + 0 <- (253,0) 0 8,0 0 2 0.000001836 1322 Q FWS [kworker/0:3] 8,0 0 3 0.000007583 1322 G FWS [kworker/0:3] 8,0 0 4 0.000008596 1322 P N [kworker/0:3] 8,0 0 5 0.000011182 1322 I FWS [kworker/0:3] 8,0 0 6 0.000013240 1322 U N [kworker/0:3] 1 8,2 0 7 0.000260525 393 A WM 1682144 + 32 <- (253,0) 736 8,0 0 8 0.000261325 393 A WM 3781344 + 32 <- (8,2) 1682144 8,0 0 9 0.000262451 393 Q WM 3781344 + 32 [xfsaild/dm-0] … CPU0 (sda): Reads Queued: 8, 620KiB Writes Queued: 37, 689KiB Read Dispatches: 8, 620KiB Write Dispatches: 29, 689KiB Reads Requeued: 0 Writes Requeued: 0 Reads Completed: 8, 620KiB Writes Completed: 41, 689KiB Read Merges: 0, 0KiB Write Merges: 2, 20KiB Read depth: 1 Write depth: 8 IO unplugs: 18 Timer unplugs: 0 Throughput (R/W): 6KiB/s / 7KiB/s Events (sda): 339 entries Skips: 0 forward (0–0.0%)
- Данный вывод состоит из 2 блоков:
события(на подобии tcpdump)
статистика, которая разбита по ядрам CPU
События
Стандартный вывод статистики состоит из следующих полей данных
%D %2c %8s %5T.%9t %5p %2a %3d
%D — Устройство, на котором было выполнено событие, Мажорная и минорная версия, соотношение можно посмотреть через вывод утилиты lsblk
[root@centos7 blktrace]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 7G 0 part ├─centos_centos7-root 253:0 0 6,2G 0 lvm / └─centos_centos7-swap 253:1 0 820M 0 lvm [SWAP] sr0 11:0 1 1024M 0 rom
%2c — Номер ядра CPU, которое обрабатывало данное событие.
%8s — Порядковый номер события
%5T.%9t — Секунды и наносекунды с момента запуска дампа.
%5p — PID процесса
%2a — Действие с блоком данных, основные это:
С — complet. Запрос выполнен, но это не означает что он выполнен успешно.
Q — queued. Проверка очереди.
A — remap. Передача события на устройство ниже. Например с LVM на диск.
G — get request. Отправка запроса на устройство для выделения контейнера структуры данных.
I — inserted. Добавление в очередь планировщика Linux.
D — issued. Передача блока на драйвер устройства.
M — back merge, F — front merge. Есть блоки которые имеют общую границу данных, и могут быть объедены в одну операцию.
%3d — RWBS поле, где:
R — чтение, W — запись, D — отмена операции, B — барьерная операция, S — синхронизация.
Статистика
После событий идет блок статистики по ядрам CPU, в которой агрегирована информация по всем действиям, сколько событий было, сколько было смерженых событий и выполненных.
Практическое применение
Запускаем запись дампа на устройстве SDA
[root@centos7 blktrace]# blktrace -d /dev/sda -o sda
В другой консоли запускаем тестовое события записи данных на блочное устройство
[root@centos7 ~]# sync; echo 1 > /proc/sys/vm/drop_caches [root@centos7 ~]# dd if=/dev/urandom of=/tmp/test bs=4k count=1024 & [1] 3944
Сбрасываем дисковы кеш и запускаем копирование.
[root@centos7 blktrace]# blkparse -i sda.blktrace.0 | awk '$5==3944 {print}' | wc -l 324
Всего получилось событий 324, все их рассматривать не будем, разобьем на 2 этапа, чтение и запись.
Чтение
Возникает вопрос, откуда у нас в данном дампе чтение, если мы читали из псевдоустройства, ответ — т.к. перед запуском команды мы сбрасывали дисковый кеш, то для поднятия команды и зависимых библиотек потребовалось чтение с дисков.
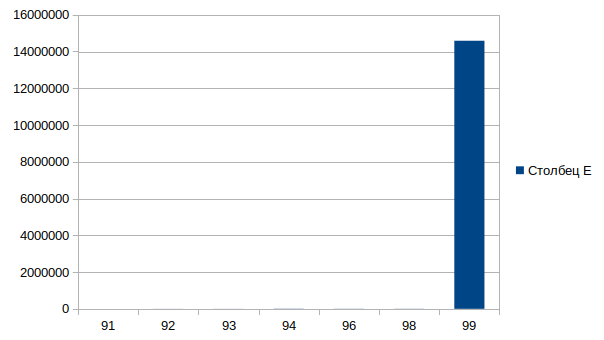
Возьмем чтение одного блока и что мы видим:
[root@centos7 blktrace]# blkparse -i sda.blktrace.0 | awk '$5==3944 || $5==0 {print}' | grep "13560296\|11461096" 8,2 0 91 4.746796216 3944 A R 11461096 + 32 <- (253,0) 9779688 8,0 0 92 4.746797670 3944 A R 13560296 + 32 <- (8,2) 11461096 8,0 0 93 4.746799869 3944 Q R 13560296 + 32 [bash] 8,0 0 94 4.746809045 3944 G R 13560296 + 32 [bash] 8,0 0 96 4.746814636 3944 I R 13560296 + 32 [bash] 8,0 0 98 4.746820116 3944 D R 13560296 + 32 [bash] 8,0 0 99 4.761404769 0 C R 13560296 + 32 [0]
91 — событие пришло на устройство 8,2 и выполнился remap на устройство 8,0. При этом хвост сообщения(<- (253,0) 9779688) нам говорит, что и это событие пришло нам с устройства 253,0, но так как дамп мы снимали с устройства 8,0 мы его не видим. Так же обратите внимание что сам блок меняется, так как у каждого устройства он свой.
lsblk — поможет нам определить трассировку события
[root@centos7 blktrace]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 7G 0 part ├─centos_centos7-root 253:0 0 6,2G 0 lvm / └─centos_centos7-swap 253:1 0 820M 0 lvm [SWAP] sr0 11:0 1 1024M 0 rom
92 — событие remap на устройство 8,0
93 — queued. Проверка io очереди.
94 — get request. Проверка готовности устройства.
96 — inserted. Добавление команды чтения в очередь.
98 — issued. Отправка на устройство.
99 — complet. Уведомление от устройства что задача выполнена.
Если разбирать данное событие то видим что оно выполнилось успешно, за 0.014608553 секунды, что довольно быстро, но если разбить на этапы, то получим что самое медленная операция между 98 и 99 событием 0.14584653 секунды.
Запись.
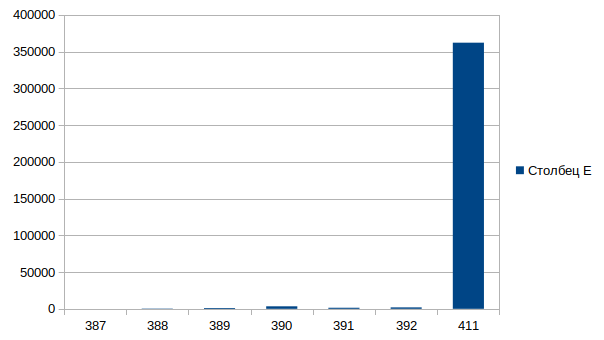
Аналогично проведем проверку одного блока на запись
[root@centos7 blktrace]# blkparse -i sda.blktrace.0 | awk '$5==3944 || $5==0 {print}' | grep "5804632\|7903832" 8,2 0 387 4.964830989 3944 A W 5804632 + 1024 <- (253,0) 4123224 8,0 0 388 4.964831398 3944 A W 7903832 + 1024 <- (8,2) 5804632 8,0 0 389 4.964832500 3944 Q W 7903832 + 1024 [bash] 8,0 0 390 4.964835923 3944 G W 7903832 + 1024 [bash] 8,0 0 391 4.964837361 3944 I W 7903832 + 1024 [bash] 8,0 0 392 4.964839281 3944 D W 7903832 + 1024 [bash] 8,0 0 411 4.965201318 3944 C W 7903832 + 1024 [0]
Состав событий идентичен как для чтения, повторятся не буду.
Итоговый временной график следующий
Итоги
Как мы видим(и в принципе знаем), что самое узкое место PC — это блочное устройство, но умение пользоваться данным инструментом, может определить другие проблемы, например переполнение очереди, проводить исследование работы планировщиков и т.д.
Bonus.
Утилита BTT, визуализация дампа )
[root@centos7 blktrace]# btt -i sda.blktrace.0 -o sda [root@centos7 blktrace]# cat sda.avg ==================== All Devices ==================== ALL MIN AVG MAX N --------- ------------- ------------- ------------- ----------- Q2Q 0.000003499 0.169834820 8.225748599 106 Q2G 0.000000420 0.000001949 0.000009176 104 G2I 0.000000715 0.000059087 0.000447256 104 Q2M 0.000000983 0.000001636 0.000002793 3 I2D 0.000000259 0.001408037 0.018125005 104 M2D 0.000659133 0.000666699 0.000675267 3 D2C 0.000101756 0.020238508 0.042954645 107 Q2C 0.000108231 0.021685131 0.051552538 107 ==================== Device Overhead ==================== DEV | Q2G G2I Q2M I2D D2C ---------- | --------- --------- --------- --------- --------- ( 8, 0) | 0.0087% 0.2648% 0.0002% 6.3111% 93.3290% ---------- | --------- --------- --------- --------- --------- Overall | 0.0087% 0.2648% 0.0002% 6.3111% 93.3290%
- Что это все обозначает:
Q2Q — время между трассировками очереди системы
Q2I — Время, необходимое для вставки или объединения входящего ввода-вывода в запрос очередь.
Q2G — Время, необходимое для получения запроса.
G2I — Время, необходимое для помещения этого запроса в очередь запросов
Q2M — Время на merge
I2D — Время, затраченное на очередь запросов.
D2C — Время выполнения запроса, с момента передачи на устройство.
Q2C — Q2I + I2D + D2C