Маленький CI для маленького блога

Photo by Collab Media on Unsplash
Давно я не писал в блог, пора это исправлять.
И так недавно все же дошли руки до написания CI/CD процесса для автоматической публикации новых статей по взрослому через систему контроля версии.
Посмотрим что из этого вышло.
Блог можно рассматривать как продукт, и каждую новую статью как улучшение и новую версию.

Если рассмотреть каноническое представление об процессе CI(continuous integration) [1], как на рисунке выше, то мы можем выделить следующие шаги:
Стадия фиксации - подтверждающая, что система работоспособна на техническом уровне. На этой стадии приложение компилируется и проходит через набор автоматических тестов. Кроме того на этой стадии выполняется анализ кода.
Автоматический приемочный тест и Автоматический тест производительности - подтверждающая что система работает на функциональном и не функциональном уровнях. На этой же стадии проверяется, соответствует ли поведение системы потребностям пользователей и требованиям спецификации.
Ручное тестирование - выполняется исследование тестирование, оценивается удобство приложения, проверяется внешний вид и поведение системы на различных платформах.
Релиз - предоставление системы пользователям в виде упакованного приложения или путем развертывания в рабочей и отладочной среде.
Все эти шаги, кроме автоматических тестов, и их применение для блога мы рассмотрим далее.
Стадия фиксации
Стадия фиксации начинается с изменения состояния проекта, которое фиксируется в системе управления версии, а заканчивается отчетом о неудаче или, если завершение стадии успешное, созданием коллекции двоичных артефактов и пригодных к развертыванию сборок, использующих на последующих стадиях тестирования и поставки релиза.
—Jez Humble and David Farley
Git как распределенная система управления версиями, давно уже себя зарекомендовала как лучшая система и опрос проведенный уже в далеком 2014 году на habr уже тогда показывал статистику использования более 70%, по этому выбор системы контроля версии был очевиден.
В качестве хостинга git-репозитория был выбран крупнейший на данный момент веб-сервис GitHub, вот несколько причин выбора:
Codespaces позволяет быстрее приступить к написанию кода с помощью полностью настроенных, безопасных облачных сред разработки, встроенных в GitHub.
Issues создавайте проблемы, разбивайте их на задачи, отслеживайте взаимосвязи, добавляйте настраиваемые поля и ведите обсуждения.
Code Review легкие инструменты проверки кода встроены в каждый запрос Pull Request.
GitHub Actions упрощает автоматизацию всех рабочих процессов программного обеспечения. Создавайте, тестируйте и развертывайте свой код прямо из GitHub.
И так с хранением кода мы разобрались, но что это будет за код. Поиск по инструментам привел меня к проекту Nikola — Static Site Generator, несколько возможностей инструмента:
Генерация статического HTML контента: Статические веб-сайты безопаснее, используют меньше ресурсов и избегают привязки к поставщику и платформе. Можно разместить веб-сайт Nikola на любом веб-сервере, большом или маленьком. Это просто набор HTML-файлов и данных.
Быстрота и инкрементные сборки: Nikola работает быстро. Он использует doit, который обеспечивает инкрементальные сборки — другими словами, собирать только те страницы, которые нуждаются в этом.
Поддержка нескольких форматов: Из коробки поддерживаются reStructuredText, Markdown, IPython (Jupyter) Notebooks и HTML, а также есть плагины для многих других форматов.
Встроенные компоненты: Nikola поставляется со всем необходимым для создания современного веб-сайта: блог (с комментариями, тегами, категориями, архивами, каналами RSS/Atom), удобными галереями изображений и листингами кодов.
Поддержка нескольких языков: Можно писать посты на нескольких языках и иметь ссылки между разными версиями поста.
Наличие CLI: позволяет собирать проект, создавать шаблоны новых записей и страниц.
Наличие встроенного web сервера.
Как уже было выше сказано, в качестве артефакта на выходе, мы получаем статический HTML код, который мы потом можем использовать как в качестве релиза так и на тестовом окружении. Отдельно хранить данный артефакт хранить не имеет смысла так как сборка его не занимает много времени и вычислительных ресурсов, по этому сборку данных я выполняю непосредственно при создании стенда.
В данном решении есть ряд плюсов и минусов
+ Скорость сборки, достигается за счет уже собранных ранее данных
+ Сокращение использования вычислительных ресурсов
+ Не нужно храниться данные о сборках и контролировать их очистку
- При удалении файлов страниц - собранные до удаления страницы и данные остаются
Источником данный я выбрал формат reStructuredText. Огромный плюс в том что в отличии от Markdown обладает расширенным синтаксисом. Но есть и огромный минус, приходится каждый раз вспоминать синтаксис, если пользуешься им редко.
И так подводим промежуточный итог, у нас есть инструмент Nikola для создания блога из кода, и этот код у нас хранится в системе контроля версии. Далее собираем сборочный конвейер.
Тестовая и продуктовая среда должна быть максимально приближенными, и повторяемыми. По этому будем запускать в контейнере, ряд преимуществ:
Конфигурация хранится в коде
Можно запустить локально
Быстрая сборка, при наличии кэш данных
Запуск на любой современной ОС Linux
Изолированное окружение от хост-системы
Запускать контейнеры будем через утилиту docker compose, через переменные окружения мы можем формировать как продуктовое окружение так и тестовое.
Окружение появилось, приступаем к тестированию:
Сборка окружения, так как новой версией можем быть не только добавление нового поста, но и обновление самого окружения, мы должны быть полностью уверены что оно собирается.
Запуск линтеров, так как исходные данные у нас хранятся в reStructuredText то желательно перед сборкой проверить его синтаксис, для этого будем использовать пакет restructuredtext-lint позволяющий быстро проверить наш код на ошибки синтаксиса.
Сборка статического контента, на данном этапе получим сформированный HTML контент, ну или узнаем об ошибке сборки.
Ну и так как наш продукт это блог, то проверяем правописание. После долгих исследований лучшие результаты, по работе с русским языком, показал пакет pyspelling в связке с hunspell.
Теперь как бы не запутаться в порядке шагов, будем объединять. Тут мне показалось подходящим использовать инструмент GNU make, выглядит проще чем скрипт на bash, а за счет target и dependencies мы можем формировать сценарии использования, итого у нас появились следующее:
build - Сборка окружения, линтеры, сборка статических данных
test - Запуск проверки правописания
start - Запуск приложения
stop - Остановка приложения
console - Дополнительный target для диагностики работы приложения в окружении.
Так же в Makefile мы определяем текущее состояние и параметры среды, и если это ветка системы контроля версии main то это нам говорит, что необходимо запустить продуктовое окружение, и тестовое, если ветка не соответствует main
Ручное тестирование
И так статья написана, пришло время создавать в системе контроля версии Pull Request на ветку main. И вот тут как раз запуститься CI процесс который подготовит нам тестовое окружение, которое мы можем посмотреть глазами.
В рамках проекта GitHub подготовлены self-hosted runners по одному для тестовой и продуктовой среды. GitHub Actions поймав запрос на слияние с main веткой запустит, на тестовой среде, задачу на сборку окружения.
Тестовое окружение будет запущено в отдельном Docker контейнере и будет доступно по отдельному доменному имени dev.su-blog.ru
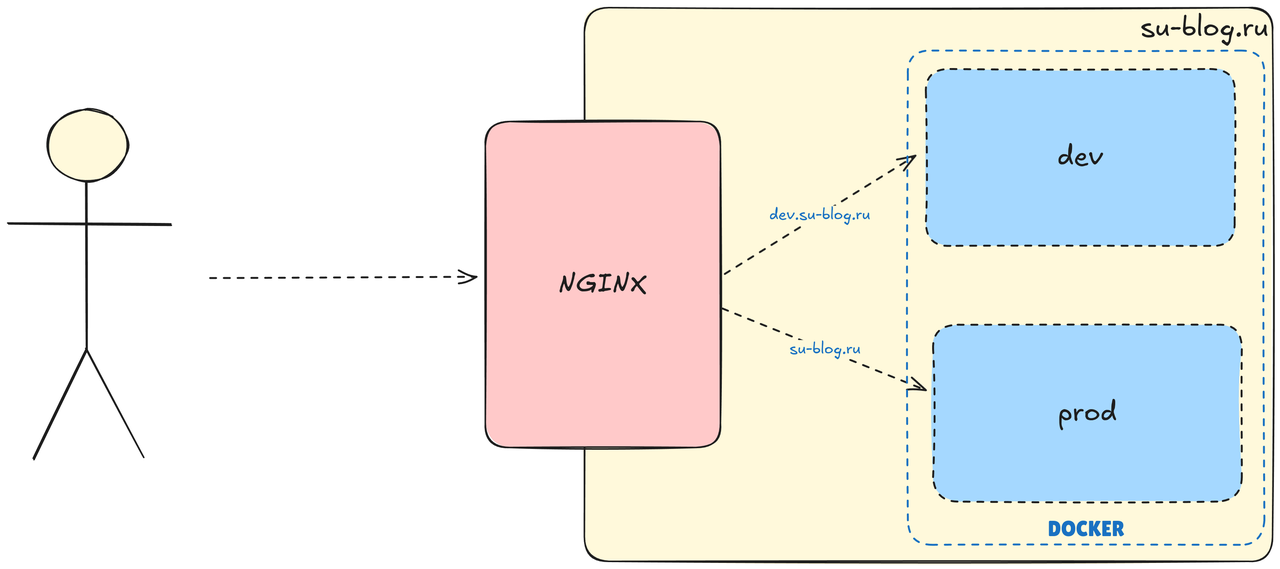
После проверки отображения и функциональности, можно приступать к слиянию на ветку main.
Релиз
Как только будет появится новый commit на ветке main, будет запущено обновление продуктового окружения. Отличия от создания тестового окружения только в том что запуск проходит на отдельном self-hosted runner, параметры окружения формируются автоматически на основе ветки системы контроля версии.
Выводы
Не хотелось быть сапожником без сапог, что и подтолкнуло меня собрать небольшой, но функциональный конвейер для блога.
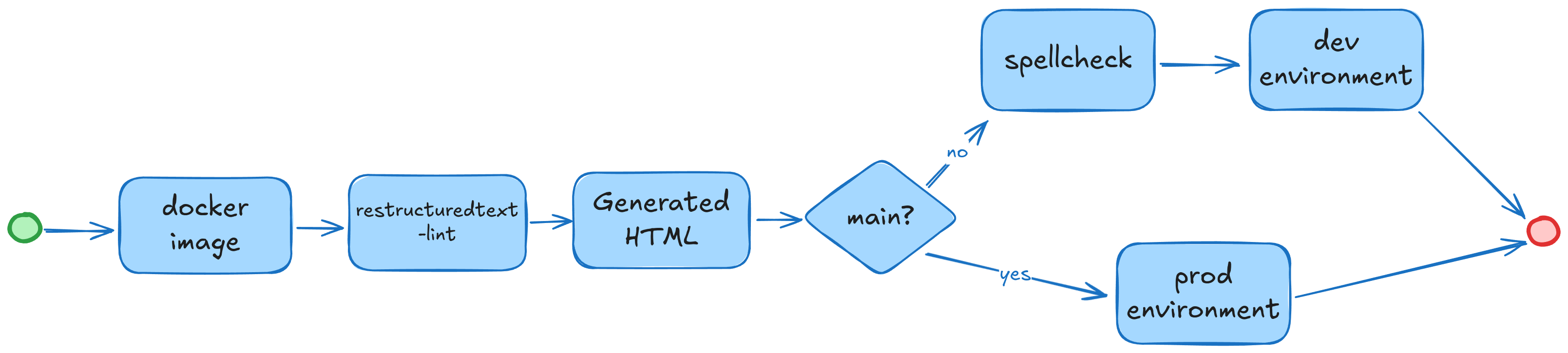
Схематично он выглядит сейчас так.